PushMetrics allows you to develop even complex reporting workflows in a simple, straightforward way - all from inside your notebooks.
What is a workflow?
For us, a (data) workflow means an executable process that performs one or many different tasks in a specific order.
In most cases, this means getting data from someplace, manipulating it, and then - maybe only under certain conditions - sending the data somewhere else.
You might also call this a data pipeline or DAG (Directed Acyclic Graph).
Here's a simple example:

A basic data workflow
Notebooks are Workflows
In PushMetrics, every notebook is a workflow - if it has at least one executable block (that is SQL queries, API calls, or message blocks).
This is automatically the case. You don't need to turn a notebook into a workflow or build workflows in a different place - notebooks are compiled into executable DAGs automatically.
The example graph above could look like this in a notebook:
- a SQL query
- an Email block, using data from the SQL query
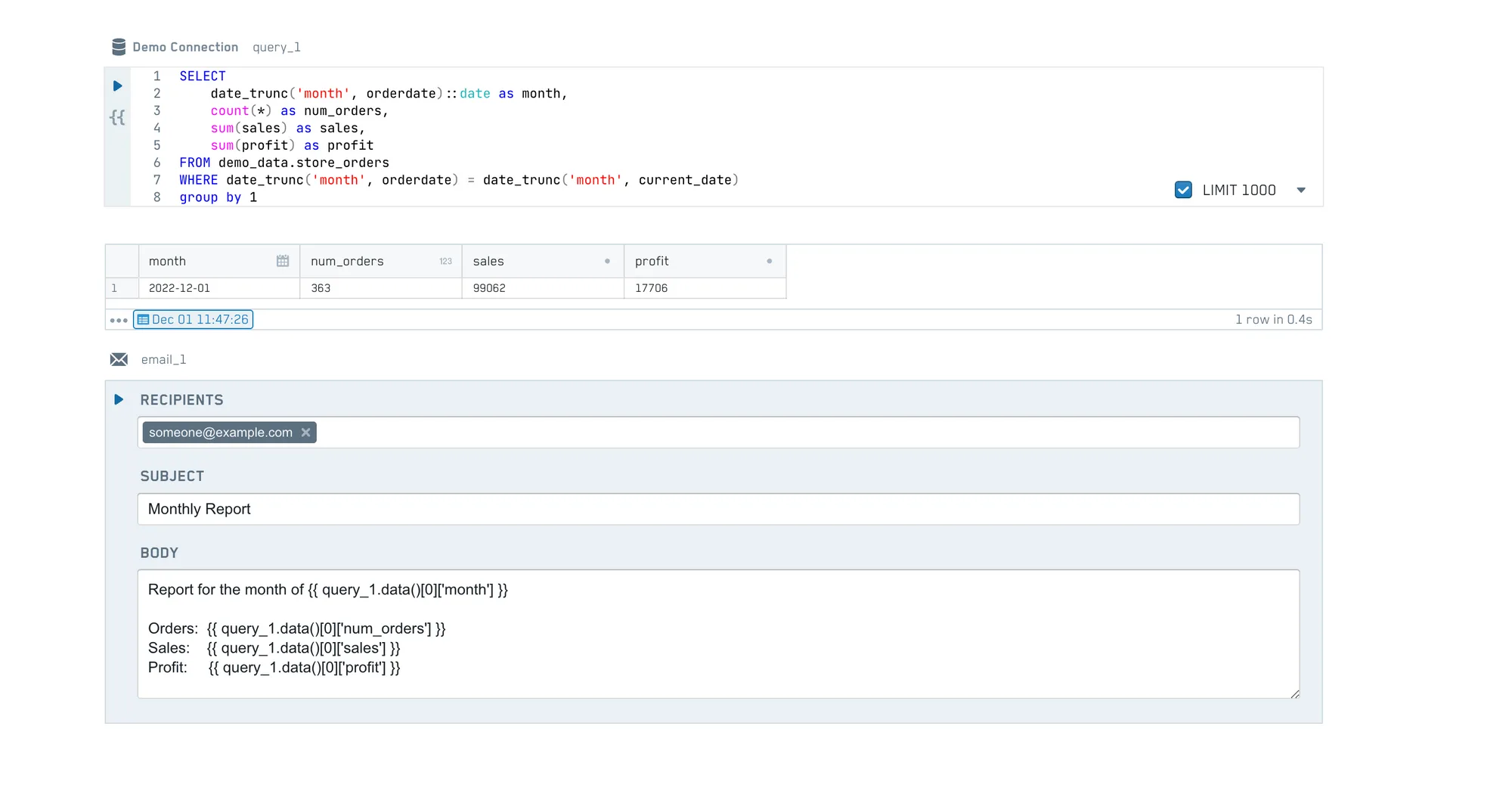
A simple reporting workflow in a PushMetrics notebook
On execution, PushMetrics detects that the email needs the results of the query. Therefore it will run the query first and only send the email afterwards. The order of the blocks on the page is irrelevant.
What is a DAG?
A DAG is an acronym for Directed Acyclic Graph, which is a fancy way to say that a workflow:
- can have tasks with dependencies between each other (graph)
- can not have circular dependencies (acyclic)
- is always executed in a specific order (directed)
The most common example of a DAG is probably a simple spreadsheet: Cells can reference each other, but not in a circular way. Then, the spreadsheet figures out in which order to calculate all the cells.
Notebooks are DAGs
Translated to a PushMetrics notebook this means:
- Blocks can reference the contents of other blocks (e.g. the SQL code or the results of a query can be used in another block). This builds a dependency between the blocks, which could be represented as a graph.
- Blocks can not have circular dependencies. For example, if the results of
query_1are used inquery_2, you can't use results fromquery_2inquery_1. - Blocks in a notebook are executed in order. The exact order depends on the specific dependencies between the blocks. Blocks with no dependencies can be executed at the same time, whereas blocks that depend on each other can only be executed one after another.
The good news is that you don't really need to know or worry about this when working in PushMetrics. Compiling the notebook into a DAG and executing it in the right order is something that just happens in the background automatically.
How to build workflows in PushMetrics notebooks
In order to build workflows in PushMetrics, we need to
- define executable tasks, e.g. SQL queries, email messages, API calls, or Slack messages
- (optionally) reference data from one task in other tasks, which creates dependencies between tasks
- (optionally) define custom execution logic, e.g. running a task only under a certain condition or repeating a task multiple times.
In PushMetrics, tasks are defined by blocks in the notebook, dependencies and execution logic are specified using Jinja templating syntax.
Defining Tasks
At this point, PushMetrics supports the following executable tasks:
- SQL Queries
- API Requests
- Emails
- Slack Messages
You can add such a task by simply adding a block with that type to a notebook.
Task Dependencies
Task dependencies are created when data from one block is used in another block.
For example:
- The value of a parameter block called
parameter_1can be referenced in a SQL query like this{{ parameter_1 }} - The SQL statement of a block
query_1can be referenced in another query like this{{ query_1 }} - The results of
query_1can be referenced like this{{ query_1.data() }}(which returns a JSON representation of the results table) - The value of the first row of the column
examplein the results ofquery_1would be called like this:{{ query_1.data().[0]['example'] }} - Similarly, the results of an API request are called like this:
{{ api_call_1.data() }}
Execution Logic
Execution logic is expressed using Jinja syntax, simply by wrapping the executable blocks inside of Jinja expressions.
For example:
-
You can add conditional branching logic like this:
{% if some_condition = true %} *do this* {{ else }} *do that* {% endif %} -
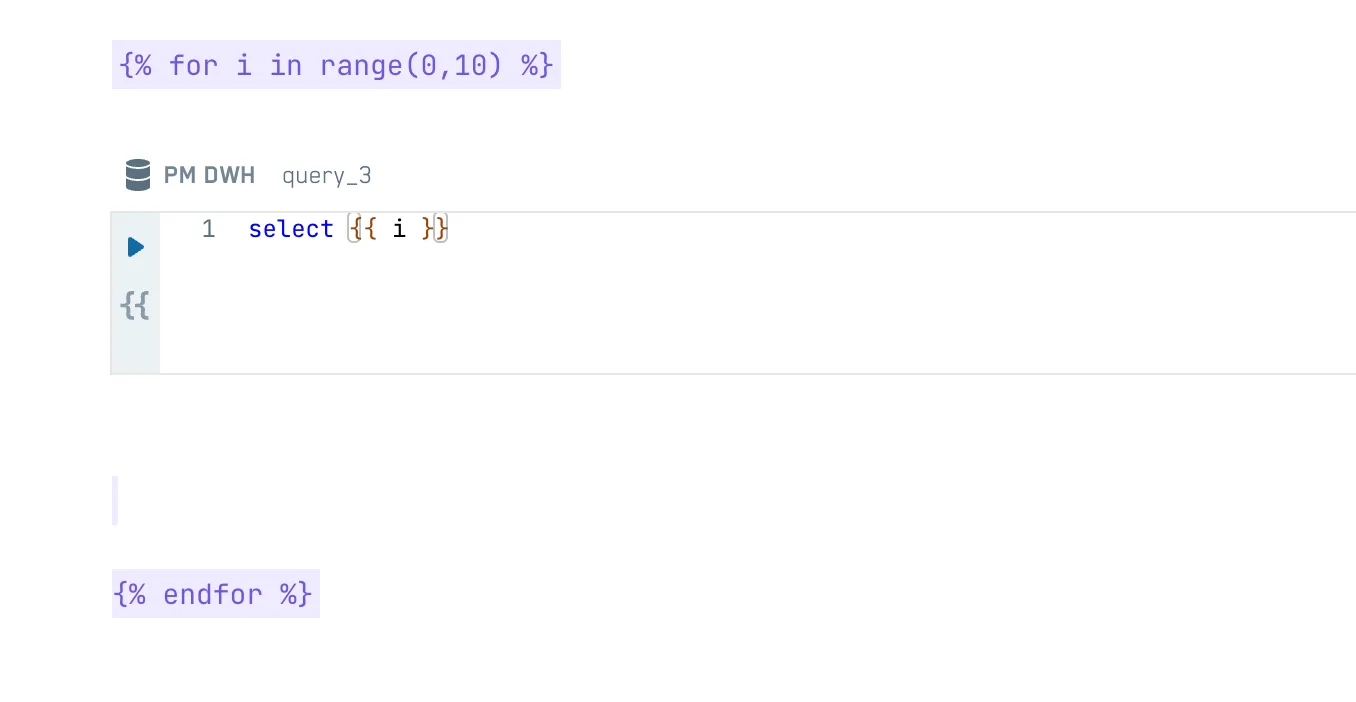
Or loop over a set of tasks:
{% for i in range(0,10) %}
*do a task using* {{ i }}
{% endfor %}
In a notebook, it could look like this: